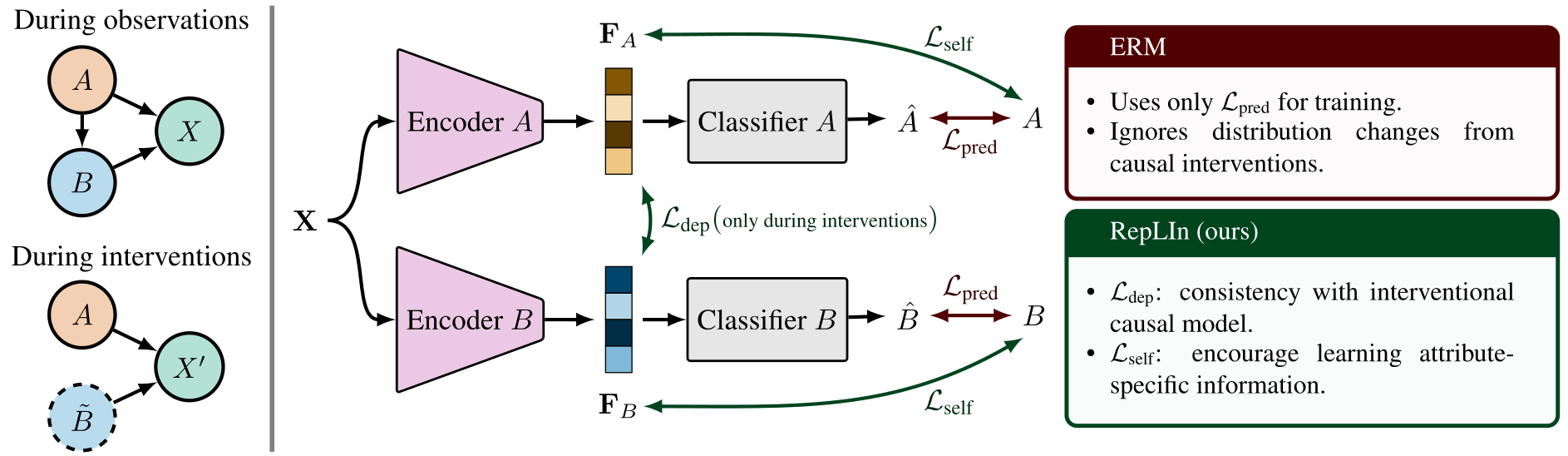
How can you make your representations robust against distribution shifts due to causal interventions? In this paper, we propose a training algorithm to learn discriminative representations that are robust against known interventional distribution shifts. The key challenge will be in achieving our goal when the amount of available interventional training data is far less compared to the passively collected observational data.
For details, please refer to our paper that appeared in the Transactions on Machine Learning Research in 2025.
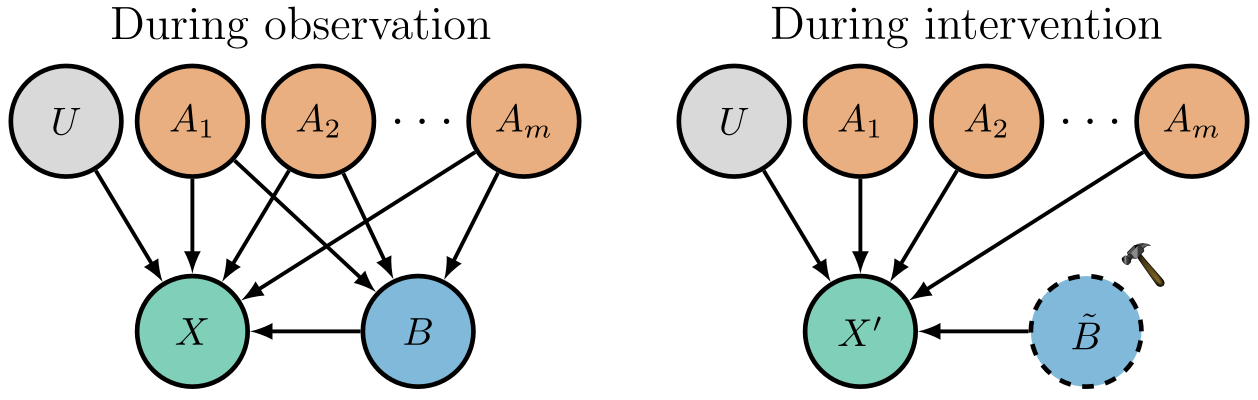
We are interested in learning individual representations for causally-related random variables for some downstream prediction tasks. The process of manually changing the value of a variable is called causal intervention. By manually changing the value of a variable, we render it statistically independent of its parent variable in the causal graph.
This statistical independence leads to a distribution shift in the observed data, which we will refer to as the interventional distribution shift.
Since observational samples are typically much more in number than interventional samples in the training set, the learned representations may rely on "shortcuts" that are invalid during interventions. This leads to a drop in performance for these representations on interventional data.
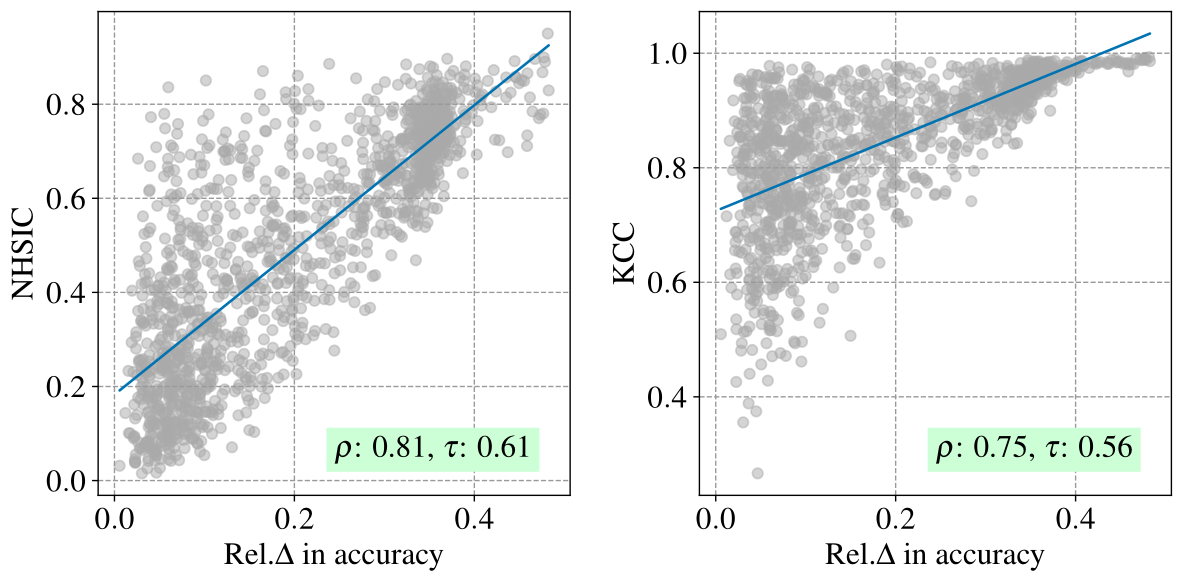
Finding #1: In the plots above, we observe that the relative drop in accuracy correlates positively with the statistical dependence (measured using HSIC and KCC) between the representations of the intervened variable and its parents.
To improve robustness of representations, we propose RepLIn, a training algorithm that explicitly minimizes statistical dependence between the representations of the intervened variable and its parents in the causal graph. Specifically, we use HSIC to compute dependence. Additionally, we also maximize the statistical dependence between a representation and its corresponding variable to ensure rich information.
We show through theory that, in the linear setting, enforcing independence between interventional features leads to lower test prediction error on interventional data.
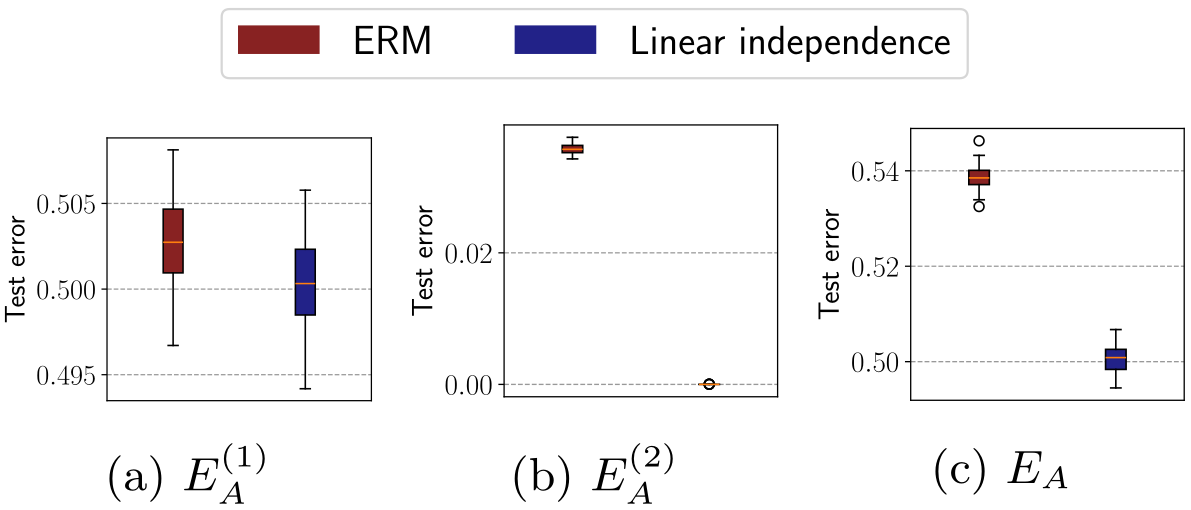
Finding #2: The plots above validate our theory: enforcing independence leads to a lower reducible error (second plot, E2) on interventional data.
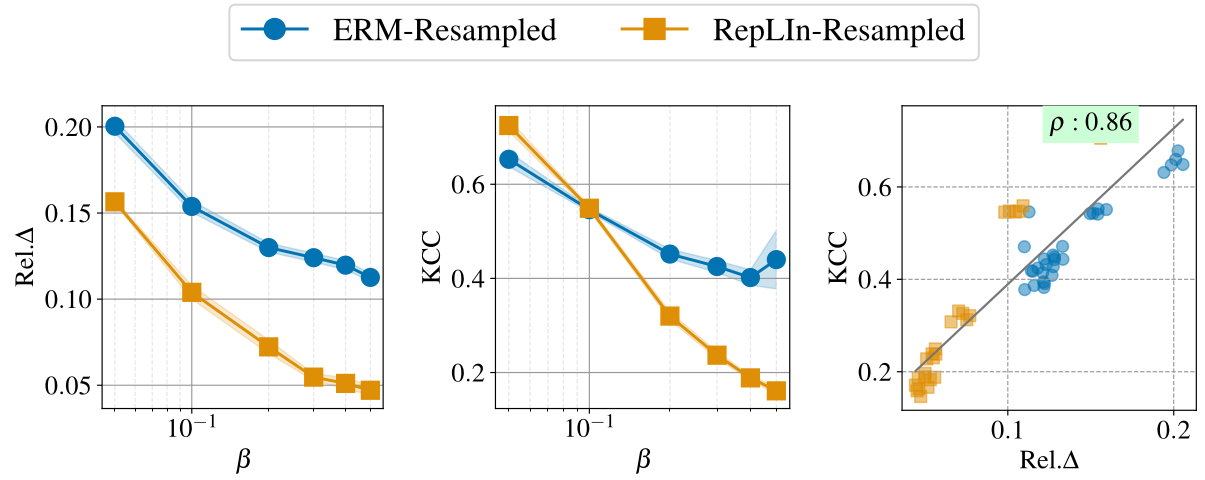
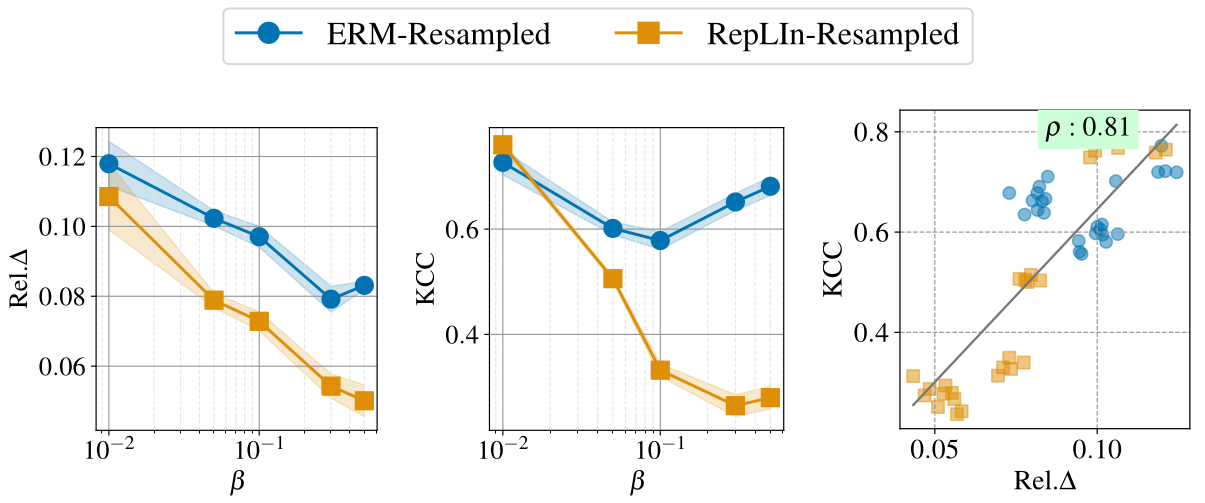
Results on pre-trained features from CelebA and CivilComments datasets for attribute prediction tasks show that RepLIn outperforms ERM baselines. They also demonstrate the correlation between interventional feature dependence and accuracy drop during interventions. More results are in the papers.
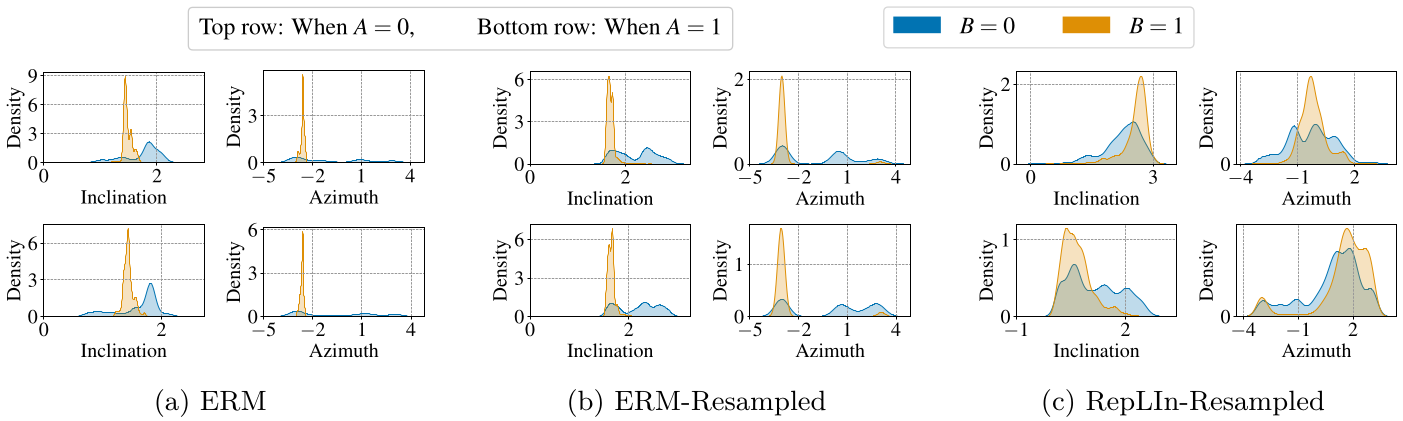
Visualizing the representations learned by ERM baselines and RepLIn reveal that RepLIn representations are more robust to intervention-time changes than ERM representations, indicated by the higher overlap between orange and blue feature histograms.
RepLIn is especially useful in scenarios where we can anticipate inference-time interventions, but have only very few interventional training samples to learn robust representations.
@inproceedings{replin,
title={{Incorporating Interventional Independence Improves
Robustness against Interventional Distribution Shift}},
author={Gautam Sreekumar and Vishnu Naresh Boddeti},
year={2025},
booktitle={{Transactions on Machine Learning Research}},
url={https://openreview.net/forum?id=kXfcEyNIrf},}